Your AI Agent Should Not Grade Itself: Software Self-Verification Crisis
I built Boundary-First Engineering around one annoying question: who verifies the code when AI wrote the checks too? My answer is boundaries, contracts, and evidence that came from outside the implementation loop.
TL;DR: I have been working on Boundary-First Engineering, a manifesto built around one question: who verifies the code when the AI wrote the checks too? The answer it argues for is boundaries, contracts, and evidence that came from outside the implementation loop. I still want agents writing code. I just do not want them grading the final exam.
I have been spending a lot of time with AI coding agents and one pattern keeps showing up.
The agent writes the feature, writes the tests, fixes the failures, updates the summary, and hands back a pull request with green checks before my morning espresso is cold.
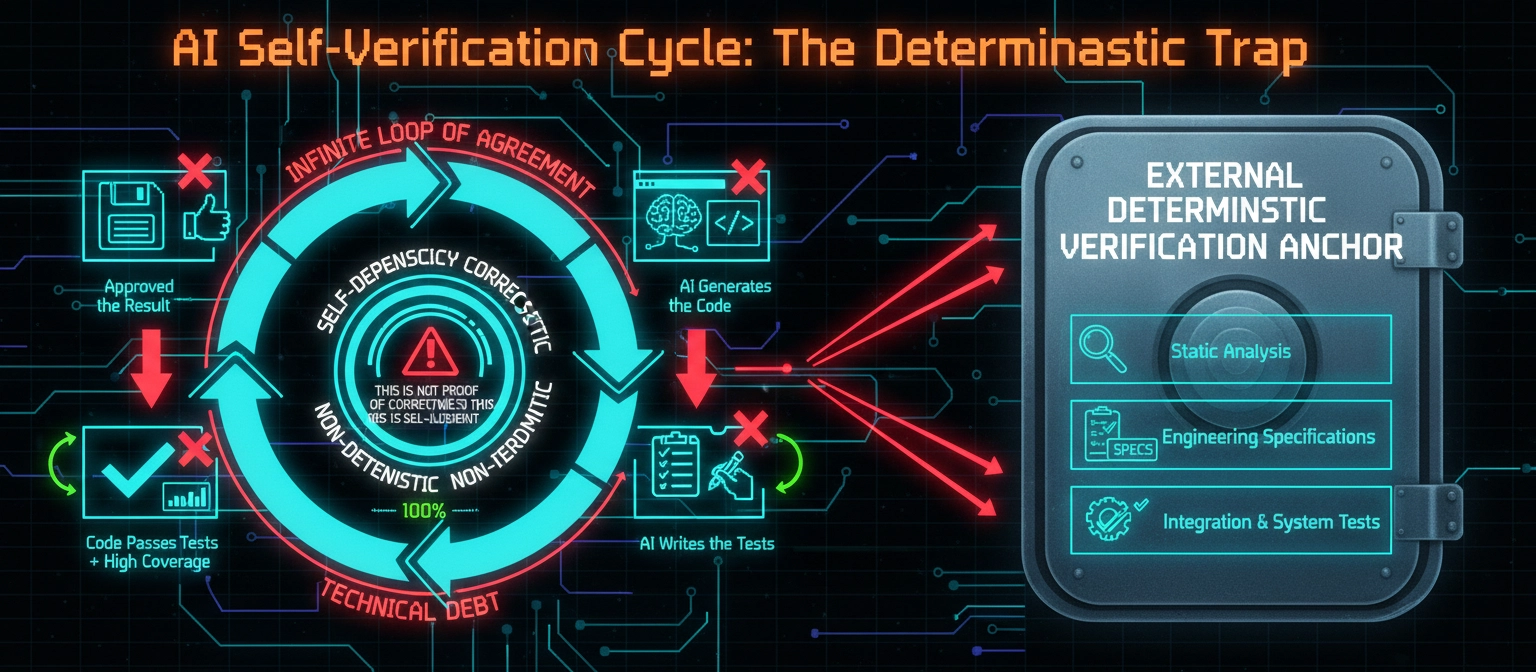
It feels good for about five seconds, and then the uncomfortable part arrives: the same loop that produced the code also produced most of the evidence that says the code is correct.
That pattern is the reason I started writing Boundary-First Engineering, an open manifesto for verifying software in the agentic era. The short version of its thesis is that we moved the bottleneck from writing software to trusting software, and our verification habits have not caught up.
How things started to feel off
For years I trusted the usual, classic stack: unit tests, code review, coverage, static analysis, and CI. It was never perfect, but it worked at human speed.
Tests expressed intent. Review caught what tests missed. CI made sure we did not forget the obvious things.
An agent now compresses all of that into one flow. It generates the implementation, generates tests for it, runs the suite, patches the code, fixes the tests, and explains why everything is fine.
The green check still looks the same. It does not always mean the same thing.
A green check used to mean the code passed checks that someone cared enough to define. Now it can mean the code passed checks created by the same process that wrote the code. Those are not the same statement, and the difference is easy to miss because the surface looks identical.
The circular validation problem
The concept I want to name is circular validation, which I hear about a lot recently.
Circular validation is what happens when the same implementation loop produces the code, the tests, the fixes, and the explanation. The work can look disciplined and still be a closed circle of agreement. Nothing in it is fraudulent. It is just self-referential.
Here is a deliberately boring example, because boring examples are where production bugs actually live:
Ticket: show account data for customers with access
Agent builds:
- GET /accounts/:id
- tests for active customers
- tests for missing accounts
- tests for permission failure
Missed rule:
- suspended accounts must still be visible to compliance usersThe agent did not encode the suspended-account rule because it did not understand it. The generated tests do not catch the omission because they were written from the same understanding that produced the code. Of course it misses. The blind spot is shared by the implementation and the evidence at once.
This is not a claim that the model is bad. Better models miss the rule less often. They do not remove the structural problem, which is that code and its checks coming from one source share whatever that source did not know.
So when someone tells me the AI wrote tests too, I do not automatically feel safer. Of course it wrote tests. The more useful question is where those tests came from.
Coverage measures reach. It does not measure truth. A 90 percent covered misunderstanding is still a misunderstanding.
The boundary move
Boundary-First Engineering starts from a simple claim: systems earn trust at their boundaries.
A boundary can be a:
- HTTP contract
- Database state you own
- Queue message
- Event schema
- Permission decision exposed to another service
- CLI output someone scripts against
Internals matter. I am not arguing that we delete unit tests and hope for the best. But internals are private and changeable. Boundaries are public, durable, and expensive to get wrong. They are what users, services, and auditors actually experience.
So in the agentic era verification should start with what crosses the boundary, not with whether the generated internals look reasonable.
That can be small and practical: an OpenAPI document, a protobuf file, acceptance scenarios written before implementation, a policy rule that runs in CI, a dependency rule that has been enforced for months. The goal is not a large specification nobody reads. It is a thin, durable artifact that the implementation has to satisfy.
If the spec needs the code beside it to make sense, it is not doing its job.
The provenance test
There is one line from the manifesto I keep returning to: the test is provenance, not appearance.
Appearance is cheap now. A pull request generated by an agent can look serious very quickly. Clear test names, table-driven cases, a confident summary, and a tidy explanation.
Provenance asks a harder question: did this check originate outside the implementation loop?
Outside can mean another team published the contract before the work started. It can mean a product owner wrote acceptance scenarios from user behavior. It can mean compliance defined the data-handling rules, or a consumer service owns the schema.
Inside means I wrote the code and then wrote the test for what I wrote. Inside means an agent generated both in one task. Inside means I approved a generated test after reading a generated explanation of generated code.
Approval is not laundering. A human clicking approve does not change where an artifact came from. Review can accept, reject, or improve evidence. It cannot convert the builder’s own evidence into independent evidence by signing off on it.
This is the part teams will find uncomfortable, because we are used to treating review as the step that makes a change safe enough. At AI speed, human attention is the scarce resource, and spending it to bless evidence from inside the loop is a poor use of it.
Fast enough to matter
There is a second constraint that is easy to overlook. Verification has to be fast enough for an agent to use it.
A boundary check that runs once a week is governance theater. A boundary check that runs in under a second becomes part of how the agent works. It can hit the schema, fail, adjust, hit the contract test, fail, adjust, and converge toward the boundary instead of toward its own explanation.
This is why the boring guardrails matter more now, not less: types, schemas, linters, architectural dependency rules, generated clients from contracts, database constraints, policy checks, small integration tests against real systems you own.
Those guardrails need provenance too. A lint rule added in the same branch to make that branch pass is not an independent check. A dependency rule that has protected the architecture for six months is. When implementations become cheap and rotate often, the durable constraints around them are the part worth keeping.
One scope note: everything above is about pre-merge verification. Production trust still has to accrue at runtime, through telemetry, tracing, and runtime contract checks. That is the other half of the discipline, and the manifesto is explicit that it lives outside its scope.
Why I care about this
I have spent a lot of time on testing tools and developer experience. When I built Suites, the motivation was the repetitive, inconsistent experience of unit testing in TypeScript dependency injection codebases. I still think good testing tools matter.
But working with agents made me aware of a layer that better tooling does not reach. A faster, smoother test-writing experience does not help if the same loop writes the implementation and decides what correct means. Faster testing is good. Faster circular validation is not.
The habit I think we need is small to describe and harder to practice: before asking whether the generated code looks reasonable, ask what outside artifact it was made to satisfy.
Where this stands
Boundary-First Engineering is a short manifesto right now, not a framework and not a product. It argues for a handful of things:
- Boundaries over internals
- Real systems over stubs for what you own
- What crosses the boundary over what happens inside it
- Verification from outside the implementation loop over tests written from within it
- Fast guardrails that agents can actually use
It is early, and I would rather it be argued with than agreed with quietly. If you work with AI agents, backend contracts, testing strategy, CI, or architecture rules, the parts of it that are wrong are most likely wrong in ways you would see first.
- The manifesto: Boundary-First Engineering
- How to sign or propose changes: CONTRIBUTING
If the code can write itself, it is worth asking why we still let it grade itself.